Table of Contents
Connecting Your Data Warehouse to CaliberMind - Start Here!
Data Import and Ingestion
When initially setting up your account with CaliberMind, you have three options for connecting your Data Warehouse for data import and ingestion.
The options include leveraging BigQuery, a Google Cloud Storage Buckets, or SFTP. With each option, there are considerations to be had as it relates to data types, schema, and file structures. Please review the requirements and related documentation below.
Options for Connecting Your Data Warehouse:
Data Warehouse to BigQuery
A service account user will need to be created to access the BigQuery warehouse. If your data warehouse allows for the creation of BigQuery service account users, you can send this information to the CaliberMind team so they can provide the user with necessary permissions to read and write. Otherwise, our team will create a service account user and encryption key for you to use when authenticating to the BigQuery connection.
The CaliberMind team will create a dataset in your BigQuery environment to set as the destination. If your team is planning on sending data from multiple systems we may create multiple datasets for the end destination. If your data warehouses export functionality allows the creation of tables, your team will be able to create the tables and transfer the data directly to this dataset as required. If your data warehouse export does not allow the creation of tables, we will need to receive a schema of the various columns and their corresponding data types. Our team will then create the necessary datasets and tables for you to use as the destination location.
If your data warehouse does allow the records to be transferred directly to BigQuery and creates the tables, any data type supported by BigQuery is permitted. If data type declarations are required when creating the table’s columns, the following data types are recommended:
Data Types:
- STRING (ie. text with various types of characters, letters, numbers, etc.)
- BOOL (ie. true/false)
- DATE (ie. date without time association, ex: 2023-05-01)
- TIMESTAMP (ie. date with corresponding time, ex: 2020-06-02 23:57:12.120174 UTC)
- DATETIME (ie. date with corresponding time, ex: 2016-05-19T10:38:47.046465)
- INT64 (ie. a number without any decimal places)
- FLOAT64 (ie. a number with decimal places)
(For more information on the data types available within BigQuery, click here)
Data Warehouse to GCS
A service account user will need to be created to access the Google Cloud Storage bucket. If your data warehouse allows for the creation of Google Cloud service account users, you can send this information to the CaliberMind team so they can provide the user with necessary permissions to read and write. Otherwise, our team will create a service account user and encryption key for you to use when authenticating to the Google Cloud Storage bucket connection.
The CaliberMind team will create a bucket location in your Google Cloud Storage environment to set as the destination.
If your data warehouse export functionality allows for the creation of directories and subdirectories within this bucket, your team can transfer them as necessary. If your team is planning on sending data from multiple systems, we may create multiple directories to help keep the data sets organized (required if file collisions occur).
If your export functionality does not allow for the creation of directories and subdirectories within this bucket, we will need to know which information will be passed over so we can create the directories for you ahead of time. In this situation, the data from each entity or object will need to be passed to these specific directories within the bucket.
When sending the data the following settings are required:
File Type: Avro (preferred), Parquet, CSV, TSV
Max File Size: 4GB (note: this is the upper limit - we recommend a size in MB’s)
Field Delimiter: “,” (comma)
Compression: GZIP
Include Header: TRUE
Field Optionally Enclosed By: ‘“‘ (quote)
CaliberMind Data to Snowflake
Customers who want to manage the sync of data from CaliberMind to a Snowflake data warehouse should explore directly connecting their Snowflake to a CaliberMind-managed Google Cloud Storage bucket via a CaliberMind-provided service account. Click here for more details.
Data Warehouse to SFTP
- CaliberMind will provide an SFTP location.
- To receive the server and port information - as well to create the SFTP User's credentials:
- Within CaliberMind, click on the "Settings" icon
- Click on "SFTP" in the left menu
- The Server and Port information will be listed at the top of the screen
- To create an SFTP user, simply click on the "Create SFTP User" button at the top and follow the on-screen prompts.
Your team will be able to transfer folders and files to Calibermind via Secure File Transfer Protocol (SFTP). When sending the data, we recommend creating a GZIP of the files prior to transfer. Be sure to include headers on all tables within. When sending data from various sources, create a directory for the system and sub-directories of the various entities or objects (or conversely, use a naming prefix that indicates which system the files are from).
Note: If you are chunking the files (i.e instead of sending one large file, it is sent in multiple smaller files), all of these files must be placed in their own sub-directory. The maximum file size is 4GB.
For more information please refer to this knowledge base article.
Best Practices
Data Taxonomy & File Structure
When transferring data to CaliberMInd, we ask that the taxonomy, file structure, and data naming conventions be prepared in a way that ensures proper organization.
For the "Data Warehouse to GCS" and "Data Warehouse to SFTP" options: when transferring data, please ensure that the folders/(sub)directories follow this taxonomy:
- GCS Bucket (bucket location) OR SFTP location (root directory)
- System OR Data Source name
- System-specific input table
- Data files
- System-specific input table
- System OR Data Source name
Examples
- GCS Bucket (ex: company-123-import)
- /salesforce
- /account
- {data files}
- /campaign
- etc.
- /account
- /salesforce
- SFTP root folder (/)
- /databricks
- /marketing_activities
- {data files}
- /marketing_contacts
- etc.
- /marketing_activities
- /databricks
Once the data is received and unloaded, the CaliberMind team will create a dataset and staging tables within BigQuery that reflect the taxonomy and naming convention used for the directories and subdirectories:
GCS/SFTP Directory (customer input) | BQ Path (CM output) |
company-123-import/salesforce/account | salesforce.staging_account |
sftp/databricks/marketing_activities | databricks.staging_marketing_activities |
*Note: If your team would like to create a dedicated date-specific (ie. YYYYMMDD format) folder containing all new or updated records specific to an input table, you can add an additional date-specific subdirectory layer. For example:
- sftp/databricks/marketing_activities/20240220
- company-123-import/salesforce/account/20240220
File Naming Convention
When setting up the files to send to CaliberMind, your team must make the decision as to whether the files transferred will be a full set of data each time, or only include incremental updates and net-new records.
If your team will be sending a full set of data each time - meaning the entire contents of records for an object, entity, or table will be purged and resent each time - please ensure that all files have unique names. For instance, if chunked files are sent for the same object, entity, or table - we recommend naming the files in an incremental manner (example “salesforce_account_001”, “salesforce_account_002”, and so on).
Otherwise, if your team will be sending incremental updates and net-new records each time, the file name must include a suffix containing the year, month, day, hour, minute in YYYYMMDDHHMM format at the time that the file was created in your data warehouse (Example: salesforce_account_001_202402191843). This filename will maintain uniqueness in order to guarantee that no two files sent are ever named the same.
File Processing and Loading
When sending the data files to CaliberMind, we will need to know how the data should be processed and loaded - depending on the sync cadence that you anticipate to send the data over to us. There are 3 options available:
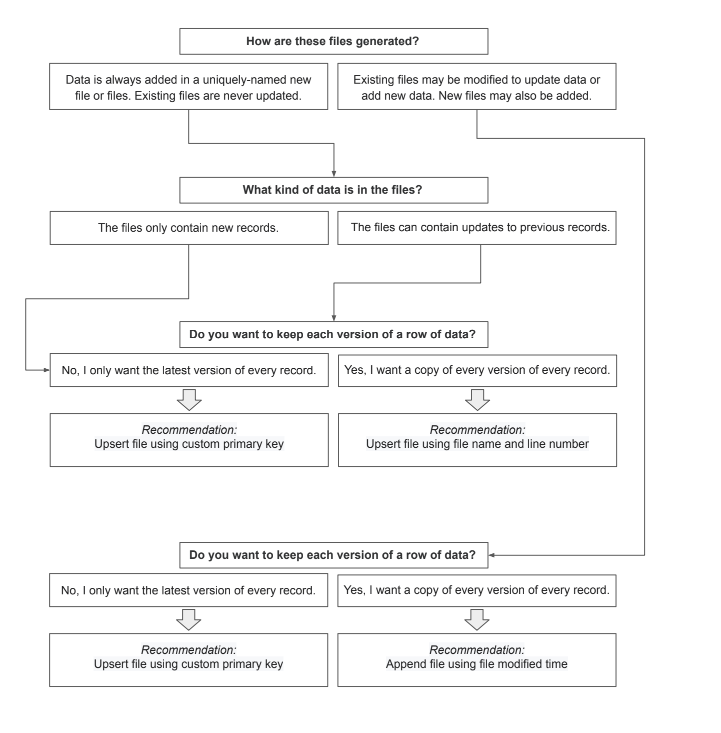
Append file using file modified time
Your files contain a mix of old and new data or are updated periodically. You want to track the full history of a file or set of files. We will upsert your files using surrogate primary keys "_file" and "_line" and "_modified". (Tip: This method is ideal for unchanging time series data - such as history or web tracking data - when the records are always unique and will always remain unmodified and unchanged)
Upsert file using file name and line number
Your files have unique names and always contain net-new data. We will upsert data using surrogate primary keys "_file" and "_line".
Upsert file using custom primary key
Your files contain a mix of old and new data or are updated periodically. you only want to keep the most recent version of every record. You will choose which primary key you use after you save and test.
*Note: To help decide on an upsert method, please see the “Data Processing Decision Tree” for a recommendation.
Data Processing Decision Tree
To assist in deciding which data processing option is best for your data, please feel free to use the decision tree below:
Pushing Your Data Warehouse Data to CaliberMind
A common question that customers ask when evaluating CaliberMind is “Can we connect our own data warehouse to CaliberMind?” While most prefer to leverage the built-in data warehouse that comes standard with CaliberMind, we recognize that some customers have invested considerable time and resources into their own data ecosystems and want to leverage those technologies. This article aims to help explain the options available to customers who wish to connect their own data warehouse to CaliberMind.
When it comes to moving data from a customer’s data warehouse to CaliberMind, we first must consider the type of data and use case.
Is the data from a CRM?
CRM data is a core part of the CaliberMind ecosystem. Leveraging this data requires substantial cleaning, normalization, and enhancement. As such, we strongly recommend that CaliberMind is connected directly to the CRM to avoid incurring substantial customization fees.
Our preferred method is to directly connect to the customer’s CRM (e.g. Salesforce, Microsoft Dynamics) to manage inbound and outbound data connections. This enables us to provide the best customer experience possible by preventing insight and reporting issues arising from non-standard CRM data structures.
Within these CRMs, we do have the ability to handle custom fields/objects. Your customer success representative can provide best practice recommendations and consult with you to understand which data points are essential for better analytics.
Is the data imported into your data warehouse from a system we commonly connect to?
A key feature of CaliberMind is the flexibility of what data we can ingest and our growing library of easy-to-use connectors. Information about what connectors we support and how to use them can be found here.
We strongly recommend directly connecting to data sources via our standard connectors where possible. These direct integrations are preferable for a number of reasons, including:
- Typically the easiest and cheapest option available
- Typically requires the least amount of technical support on the customer side
- Standardized connections allow for improved user experience through enhanced traffic monitoring and our ability to respond to source data changes (e.g. API deprecations)
Syncing Data From a Data Warehouse to CaliberMind
If you have reviewed the potential risks associated with bypassing a data source and have decided exporting data to CaliberMind from your data warehouse is still the preferred method, we can support multiple methods.
Method | Details |
You manage a process that syncs data to a cloud storage bucket (Google, AWS, or Azure). | Your data warehouse manager can set up a recurring data update to a cloud storage bucket that your company manages. From there, we'll need credentials with sufficient permissions to transfer data out of the cloud storage bucket. This may introduce an additional fee for initial setup and/or an increase in monthly fees depending on the amount and frequency of data to be synced. |
You export the data into a flat file (CSV) and send it to us via SFTP. | We can ingest data from SFTP. This may introduce an additional fee for initial setup and/or an increase in monthly fees depending on the amount and frequency of data to be synced. |
You have a BigQuery or RedShift instance. | We can connect directly to your BigQuery or Redshift instance. Note that we may need to charge a setup fee to properly map and incorporate your data into our schema and/or an increase in monthly fees depending on the amount and frequency of data to be synced. |